
Predicción de consumo eléctrico de un edificio no residencial con Machine Learning
Prediction of electricity consumption in a non-residential building using Machine Learning
Dado que las personas pasan gran parte del tiempo en el interior de los edificios, es necesario diseñar ambientes interiores que les garanticen salud, bienestar y productividad. Esto podría lograrse a expensas de la energía consumida por los sistemas de calefacción, ventilación y aire acondicionado, que representan hasta el 56% del consumo total de los edificios. Para reducir este consumo, estrategias como precooling o preheating podrían resultar beneficiosas, siempre que se cuente con información anticipada sobre el comportamiento energético del edificio. En este trabajo, se aplicaron técnicas de machine learning para abordar el rellenado de vacíos en series de datos y la predicción de consumo eléctrico del edificio del Rectorado de la Universidad Nacional de Salta.
Se utilizaron datos meteorológicos de estaciones propias, del Servicio Meteorológico Nacional y datos satelitales. Mediante redes neuronales, se rellenaron datos faltantes en las series de temperatura y radiación solar, y se entrenaron 16 modelos, basados en Deep Learning, para predecir el consumo eléctrico a diferentes temporalidades. Se evaluó el rendimiento, el horizonte de predicción y el costo computacional. Los resultados obtenidos muestran una buena capacidad predictiva del modelo seleccionado, con un valor de correlación superior a 0,95 para predicciones a 15 minutos y de 0,75 para predicciones a 6 horas.
Given that people spend a significant portion of their time in buildings, it is essential to design indoor environments that promote their health, well-being, and productivity. This could be achieved at the expense of the energy consumed by heating, ventilation, and air conditioning systems, which account for up to 56% of total building energy consumption. To reduce this consumption, strategies such as precooling or preheating could be beneficial, provided there is advanced information on the building's energy performance. In this work, machine learning techniques were applied to address gap filling in data series and predict electricity consumption at the Rector's Office building of the National University of Salta.
Meteorological data from own stations, the National Meteorological Service, and satellite data were used. Using neural networks, missing data in the temperature and solar radiation series were filled, and sixteen models based on deep learning were trained to predict electricity consumption at different time periods. Performance, prediction horizon, and computational cost were evaluated. The results obtained demonstrate a good predictive capacity for the selected model, with correlation values greater than 0.95 for 15-minute predictions and 0.75 for 6-hour predictions.
Introducción
El consumo energético de los edificios es responsable de una cantidad significativa de energía utilizada en las ciudades. La Agencia Internacional de Energía (IEA) estima, en su último informe (IEA, 2025), que el sector de la construcción y los edificios, impulsó una mayor demanda de electricidad en 2024, creciendo cuatro veces más rápido que en 2023. Así, para abordar los desafíos de la expansión urbana, la creciente necesidad de confort humano y el consiguiente aumento del consumo de energía, surgen soluciones en el desarrollo de infraestructuras edilicias inteligentes y sostenibles, donde la modelización y la previsión del consumo energético es esencial para gestionar la energía de manera eficiente.
Las técnicas basadas en datos (data-driven, D-D) emplean algoritmos de aprendizaje automático (ce, ML) para proporcionar métodos flexibles de predicción del requerimiento energético de los edificios para su posterior implementación en estrategias de control predictivo para sistemas HVAC (Bourdeau et al. 2019). El aprendizaje profundo (Deep Learning, DL) es un subgrupo dentro de ML. y permite que los modelos computacionales compuestos por múltiples capas de procesamiento aprendan representaciones de datos con múltiples niveles de abstracción, imitando así el cerebro humano. La literatura científica ha demostrado que las técnicas de DL se han aplicado con éxito en diversos tipos de predicción del consumo energético en edificios. Por ejemplo, los modelos de Redes Neuronales Recurrentes (RNN) han mostrado un rendimiento favorable en la predicción de la carga eléctrica (Kim et al. 2019; Uhrig et al. 2025). La naturaleza de los datos operacionales en las series de datos de los edificios convierte a las RNN en una técnica adecuada para la predicción del consumo energético.
En este contexto, se propone trabajar con una serie temporal de potencia eléctrica consumida por el edificio de Rectorado de la Universidad Nacional de Salta (UNSa) para el periodo desde el 1 de mayo 2024 al 31 de agosto 2025. El medidor inteligente registra los datos de consumo sólo de climatización mediante equipos de aire acondicionado. Además, se cuenta con datos climáticos de una estación meteorológica propia instalada en el edificio de Ingeniería del campus universitario. Por otro lado, se cuenta con datos públicos de variables meteorológicas registradas por el Servicio Meteorológico Nacional (SMN) y por el servicio en base satelital CAMS (Copernicus Atmosphere Monitoring Service).
El objetivo del presente trabajo es la predicción del consumo de potencia mediante una RNN a diferentes horizontes de tiempo, en función de sus valores pasados y de las variables meteorológicas que tengan influencia en su comportamiento. La estimación a tiempos futuros de la energía o potencia consumida por edificios, de uso público en este caso, permitirá estudiar y optimizar las estrategias de control de uso de sistemas HVAC y, con ello, promover escenarios de mayor eficiencia energética.
Metodología
Obtención y organización de datos
Se utilizaron datos de potencia eléctrica (kW) consumida por el edificio de Rectorado de la UNSa, medidos mediante un registrador inteligente instalado en el marco del proyecto EUROCLIMA, con registros en intervalos de 15 minutos a partir de abril de 2024. También se utilizaron datos climáticos de la ciudad de Salta, tomados de una estación meteorológica Davis VantagePro 2 del Laboratorio de Edificios Bioclimáticos, ubicada en la terraza del edificio de ingenieria de la UNSa, con datos registrados cada 15 minutos, este set cuenta con medidas de temperatura de bulbo seco (°C), humedad relativa (%), temperatura de punto de rocio (°C), velocidad del viento (m/s) y radiación solar (W/m2), entre otros. Finalmente, para completar faltantes en la serie de datos de temperatura de la estación mencionada, se emplearon datos horarios del SMN (Servicio Meteorológico Nacional | Argentina.gob.ar, s. f.) y datos satelitales de CAMS (SoDa PRODUCTS, s. f.).
Selección de variables para el análisis
Para simplificar el análisis inicial, se seleccionaron únicamente las series temporales de temperatura, radiación y consumo eléctrico. Los datos de humedad y temperatura de punto de rocío no se utilizaron, debido a su alta correlación con la temperatura de bulbo seco. La velocidad del viento puede influir a través de fenómenos como la infiltración y la convección forzada, su efecto depende de factores específicos del edificio (por ejemplo, hermeticidad y aislamiento). Para simplificar el análisis, esta variable se excluyó en la etapa inicial.
Las series de datos finales consideradas en el estudio se representan en la Figura 1.
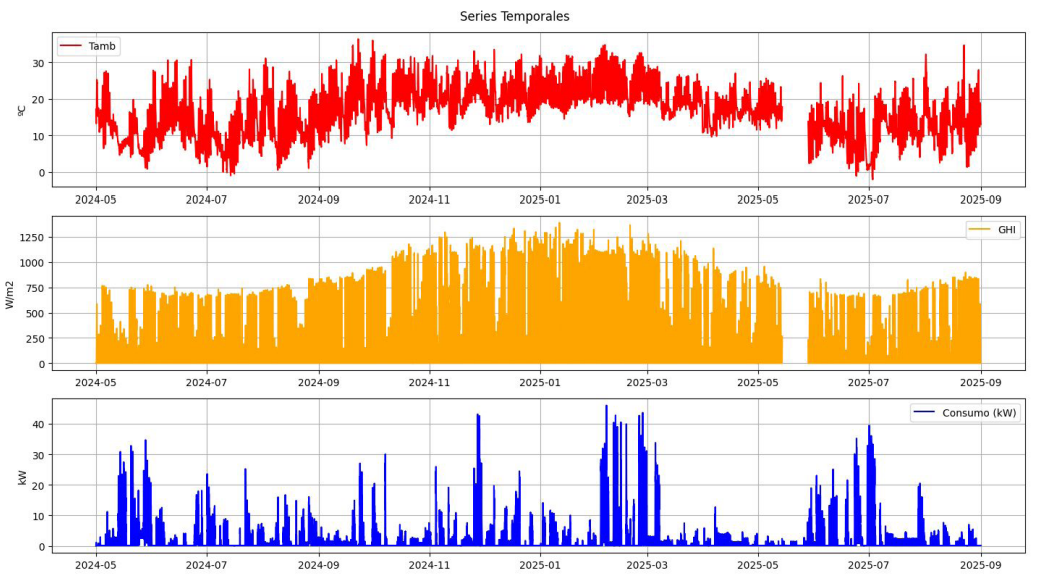 Figura 1. Conjunto de datos consideradas en el estudio: temperatura ambiente exterior (°C, arriba), irradiancia solar horizontal (W/m2, centro) y potencia eléctrica consumida (kW, abajo)
Figura 1. Conjunto de datos consideradas en el estudio: temperatura ambiente exterior (°C, arriba), irradiancia solar horizontal (W/m2, centro) y potencia eléctrica consumida (kW, abajo)
Identificación y tratamiento de datos faltantes
Se identificaron faltantes en las series de datos meteorológicos. Mediante la librería "missingno", se generó una representación visual del conjunto de datos completo para conocer la ubicación y extensión de los periodos sin datos, mostrados como franjas blancas en la Figura 2.
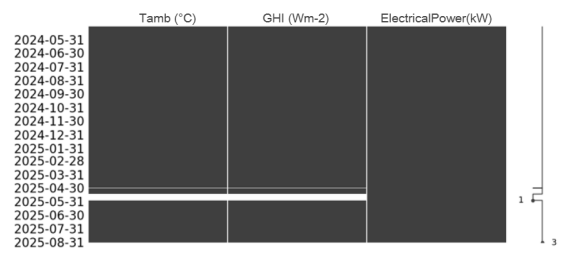 Figura 2. Visualización de la consistencia del set de datos, desde 01-05-2024 al 31-08-2025.
Figura 2. Visualización de la consistencia del set de datos, desde 01-05-2024 al 31-08-2025.
Con el objetivo de completar los huecos presentes en las series de datos seleccionadas, se decidió trabajar con modelos de machine learning, siguiendo metodologías de site adaptation. Estas correlacionan series de datos completos (satelitales o de estaciones de referencia) con los datos medidos en el sitio de interés durante periodos coincidentes, permitiendo rellenar los valores ausentes (Salazar et al. 2025; Zainali et al. 2023).
Imputación de datos de temperatura e irradiancia
La serie de datos de temperatura de la estación DavisPro de la UNSa se completó utilizando datos horarios provistos por el SMN de la estación Salta (aeropuerto). Para los datos de la UNSa, muestreados cada 15 minutos, se aplicó un remuestreo (resample) a frecuencia horaria para que ambas series posean la misma resolución temporal. Se puede realizar una primera inspección visual de ambas series en la Figura 3, donde se aprecian los datos faltantes de la serie de la UNSa. Además, se puede observar una correspondencia general de ambas series.
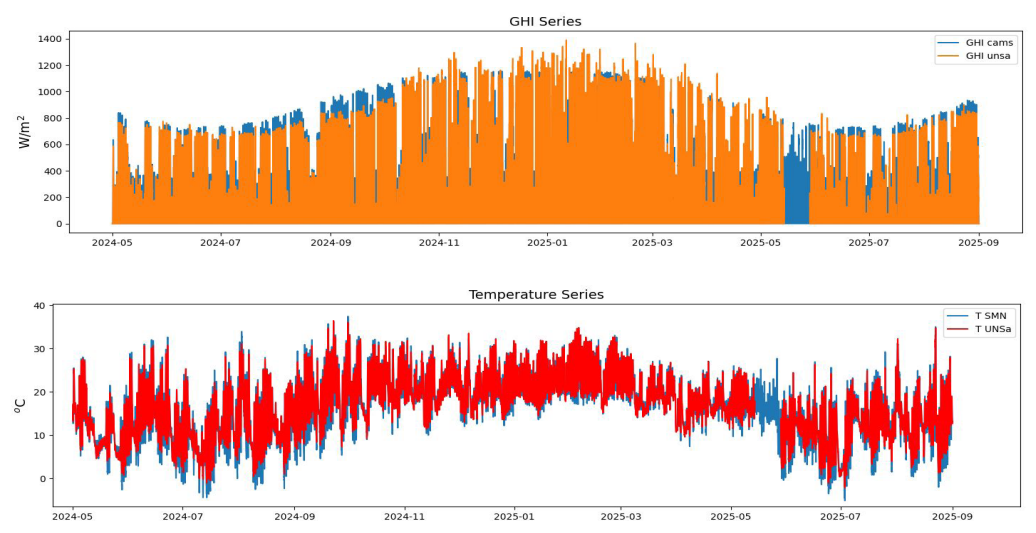 Figura 3. Comparación del ser de datos de la estación DavisProz de la UNSa y de temperatura del SMN (arriba) y de irradiancia global horizontal de CAMS (abajo), desde 01-05-2024 al 30-08-2025.
Figura 3. Comparación del ser de datos de la estación DavisProz de la UNSa y de temperatura del SMN (arriba) y de irradiancia global horizontal de CAMS (abajo), desde 01-05-2024 al 30-08-2025.
Para completar la serie de datos de irradiancia global horizontal (GHI), se utilizó la base de datos SoDa (Solar Radiation Data), generada mediante el modelo CAMS Radiation Service, con una resolución temporal de 15 minutos durante el período de interés.
Modelo de imputación y validación
Para cada variable (temperatura e irradiancia), se construyó un modelo de red neuronal de tipo Perceptrón Multicapa (MLP) (Rumelhart et al. 1986), con una única capa oculta de 10 neuronas y activación ReLU (Rectified Linear Unit). Su objetivo es modelar la relación entre las mismas variables medidas por distintas estaciones o provenientes de diferentes fuentes de datos. Para la temperatura, se utilizaron como entrada los valores horarios de temperatura del SMN, y como salida esperada, los valores correspondientes a la estación meteorológica de la UNSa. En el caso de la radiación solar, se ingresaron los datos satelitales como entrada y, como salida, los valores de la estación de la universidad.
Los datos se dividieron en conjuntos de entrenamiento (70%) y validación (30%). Cada modelo fue entrenado durante 100 épocas utilizando el optimizador Adam, que emplea una tasa de aprendizaje adaptativa, lo que mejora la velocidad de convergencia y la estabilidad en el entrenamiento (Kingma & Ba. 2014). Como función de pérdida, se utilizó el Error Cuadrático Medio (MSE). Una vez obtenidos los valores de radiación solar predichos por el MLP, se filtró la serie para asegurar que los datos tuvieran sentido físico. Para ello, se aplicó un "cereado" (forzar a o los valores de GHI) según un modelo de cielo claro (Duffie & Beckman, 2013), utilizando la librería pvlib (Pvlib Python Pvlib Python 0.13.0 Documentation, s. f.).
Finalmente, se compararon los errores de pérdida de los conjuntos de entrenamiento y validación de cada serie temporal, para verificar la ausencia de sobreajuste (overfitting) y se calcularon los errores absolutos medios (MAE). Con ello, se generó un conjunto de datos completo, revirtiendo la serie de temperatura a su frecuencia original de 15 minutos mediante interpolación temporal.
Red neuronal para predecir datos de consumo eléctrico
Para predecir el consumo eléctrico en función de sus valores históricos y de variables meteorológicas (radiación solar y temperatura ambiente), se decidió utilizar una red neuronal LSTM (Long Short-Term Memory). Se seleccionó este tipo de red por su efectividad en la captura de dependencias temporales a largo plazo, lo que permite modelar con mayor precisión series con dependencias temporales (Joseph, 2022).
El modelo desarrollado toma como entrada una secuencia de datos meteorológicos y de consumo pasados y produce como salida una secuencia (predicha) de valores de consumo eléctrico. La predicción de múltiples salidas es útil para aplicaciones de gestión energética, que requieren anticiparse a la demanda con cierto horizonte temporal.
Descripción del modelo LSTM
El modelo implementado en PyTorch, se compone de los siguientes bloques:
- Capa LSTM: Recibe secuencias de entrada con múltiples características (temperatura, radiación solar, potencia eléctrica y dos variables que indican ocupación del edificio según día y horario) y genera una representación interna de la dinámica temporal. La red está configurada para procesar lotes de datos de una dimensionalidad de: [batch_size, lookback, num_features].
- Capa lineal: Transforma la salida de la capa LSTM para obtener una predicción de consumo eléctrico por cada paso de tiempo del horizonte de predicción. La capa lineal se aplica sobre cada salida de la secuencia.
- Función de pérdida: Se utilizó el error cuadrático medio (MSELoss).
- Optimizador: Se empleó el algoritmo Adam.
El entrenamiento se realizó por lotes (batches), donde cada lote entrena al modelo a predecir una secuencia de H pasos futuros (horizon) de consumo eléctrico, a partir de las condiciones meteorológicas pasadas y la evolución del consumo en una ventana de tiempo pasado (lookback). Para los modelos evaluados, se fijó una arquitectura de 2 capas de 64 neuronas cada una. Se varió el valor de lookback entre 12, 24, 48 y 72 horas, y en cada caso se predijeron horizontes máximos de 1, 6, 12 y 24 horas. Cada una de las 16 combinaciones resultantes fue entrenada durante 100 épocas.
En base a los resultados obtenidos de los modelos anteriores, se seleccionó el de mejor rendimiento, teniendo en cuenta el compromiso entre su desempeño, el horizonte máximo de predicción y el costo computacional de su entrenamiento. Este modelo fue reentrenado, con el conjunto de datos de entrenamiento y validación, para obtener un modelo entrenado con una mayor cantidad de datos, lo cual mejora su rendimiento (Abu-Mostafa er al., 2012). Mientras que las métricas de desempeño se calcularon con el conjunto de testeo.
En la Figura 4, se observa un diagrama de flujo, con una síntesis de los procedimientos realizados a los datos utilizados.
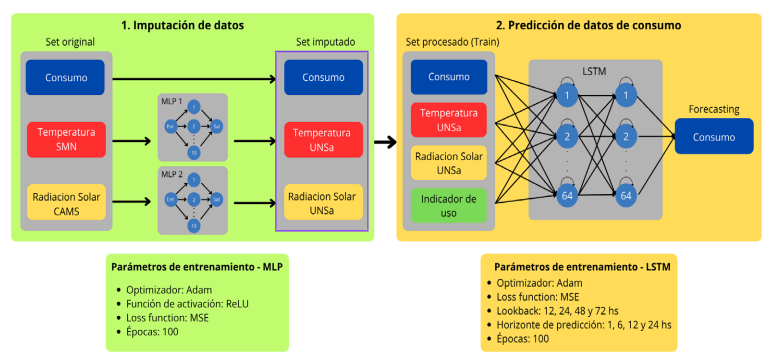 Figura 4: Flujo de datos, sintesis de procedimientos realizados para llegar al forecasting del consumo eléctrico.
Figura 4: Flujo de datos, sintesis de procedimientos realizados para llegar al forecasting del consumo eléctrico.
Resultados
Tratamiento de datos faltantes
La Figura 5 muestra la evolución de la función de pérdida durante las fases de entrenamiento y de validación de los modelos de correlación de variables meteorológicas, es decir, temperatura ambiente y radiación solar. En ambos casos, las curvas convergen adecuadamente y la brecha entre el error de entrenamiento y el de validación es mínima, lo que indica que los modelos no presentan sobreajuste (overfitting).
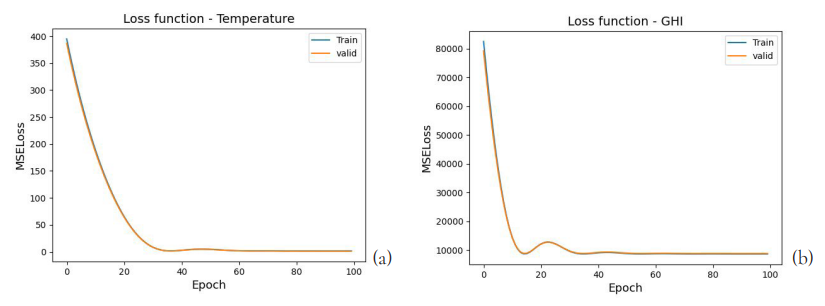 Figura 5. Evolución de la función de pérdida en las 100 épocas para los conjuntos de entrenamiento y validación de la serie de temperaturas (a) y GHI (b).
Figura 5. Evolución de la función de pérdida en las 100 épocas para los conjuntos de entrenamiento y validación de la serie de temperaturas (a) y GHI (b).
Los errores absolutos medios (MAE) calculados para los conjuntos de prueba fueron de 0.89 °C para la temperatura y de 42,6 W/m2 para la radiación solar. Estos valores confirman la robustez del método de imputación. La Figura 6 presenta las series temporales completas, destacando en azul los datos que fueron agregados por los modelos.
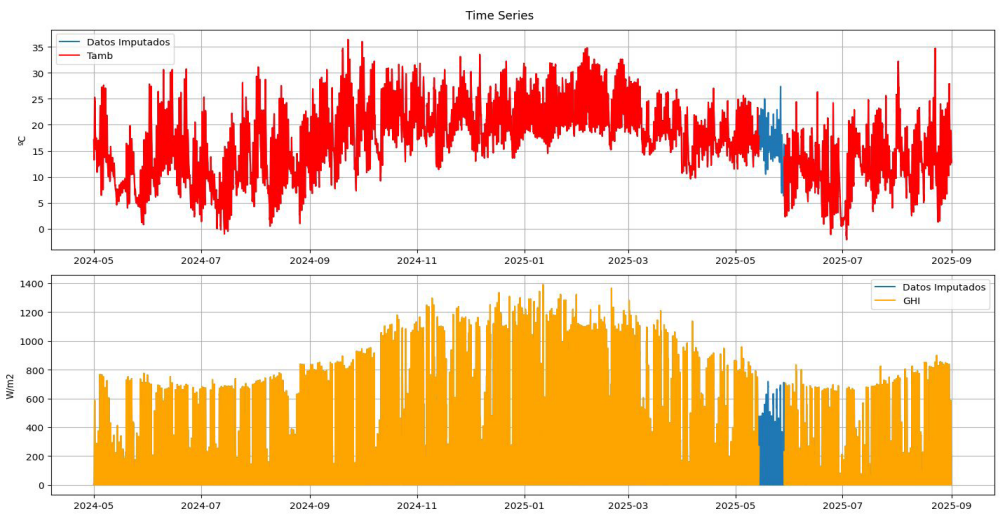 Figura 6. Datos imputados en las series temporales de temperatura ambiente (arriba) y de radiación solar (abajo). En el período del 01-05-2024 al 30-08-2025.
Figura 6. Datos imputados en las series temporales de temperatura ambiente (arriba) y de radiación solar (abajo). En el período del 01-05-2024 al 30-08-2025.
Predicción de datos de consumo eléctrico
Elección del modelo LSTM
Los resultados obtenidos para los modelos evaluados se presentan en los diagramas de Taylor de la Figura 7. Esta representación gráfica refleja el grado de ajuste de los modelos entrenados, incluyendo parámetros estadísticos como la desviación estándar relativa (σ), el coeficiente de correlación (p) y la raíz del error cuadrático medio normalizado con la desviación estándar de las observaciones (nRMSE). Ya que los modelos comparten estructura, se han etiquetado teniendo en cuenta el lookback que utilizan y el horizonte máximo de predicción que alcanzan. Por ejemplo, el modelo que utiliza lookback 12 horas (48 pasos temporales) y predice como horizonte máximo 1 hora en el futuro (4 pasos temporales) se etiqueta como lb:48, h:4.
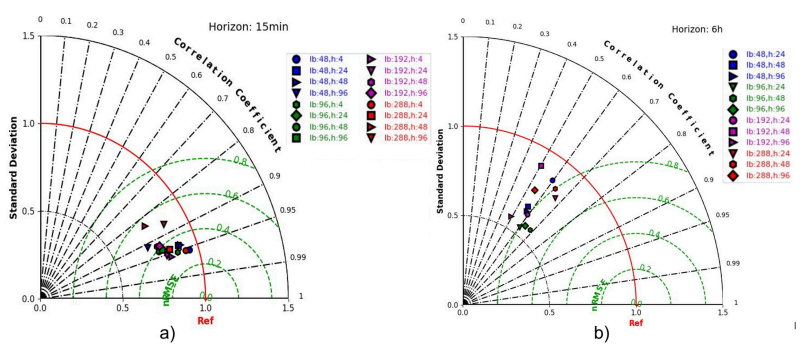 Figura 7: Diagrama de Taylor para: a) los 16 modelos evaluados, comparando sus predicciones para 15 minutos, b) los 12 modelos evaluados, que pueden predecir de 6 horas en adelante. Comparando sus predicciones para 6 horas.
Figura 7: Diagrama de Taylor para: a) los 16 modelos evaluados, comparando sus predicciones para 15 minutos, b) los 12 modelos evaluados, que pueden predecir de 6 horas en adelante. Comparando sus predicciones para 6 horas.
En la Figura 7a, se observa que los modelos que realizan predicciones a horizontes máximos menores (horizonte h:4, equivalente a una hora) presentan un mejor desempeño. No se observan grandes diferencias entre el desempeño de los modelos, donde la mayoría presenta p > 0.9 y los mejores p > 0.95, nRMSE entre 0,4 y 0,2 y σr < 1. En la Figura 7b se muestran las métricas correspondientes a una predicción de 6 horas por parte de los 12 modelos capaces de realizar este tipo de estimación. En este caso, los resultados obtenidos son más diversos y no se observa un horizonte máximo o lookback que indique que tipo de modelo se desempeñaría mejor. Los modelos lb:48, h:24; lb:288, h:24 y lb:288, h:48, son los que presentan un mejor rendimiento.
El modelo lb:48, h:24 fue seleccionado como el mejor modelo para ser reentrenado, con buenas prestaciones predictivas según Figura 7 (horizontes de 1 y 6 horas), además de ser un modelo de menor costo computacional en comparación con otros que tienen un lookback mayor.
Predicciones del mejor modelo
Una vez reentrenado el modelo seleccionado (lb:48, h:24), se utilizaron por primera vez los datos del conjunto de testeo para evaluar su rendimiento. En la Figura 8, se observa la superposición de la predicción del modelo a 15 minutos con los datos medidos. Considerando los periodos de ocupación, sombreados en verde, se observa que el modelo capta correctamente los patrones usuales de ocupación del edificio, ya que predice un consumo mínimo (base) para los fines de semana y los periodos de receso, independientemente de las condiciones meteorológicas. El periodo de receso invernal de 2025 tuvo lugar entre el 14-07-2025 y el 25-07-2025.
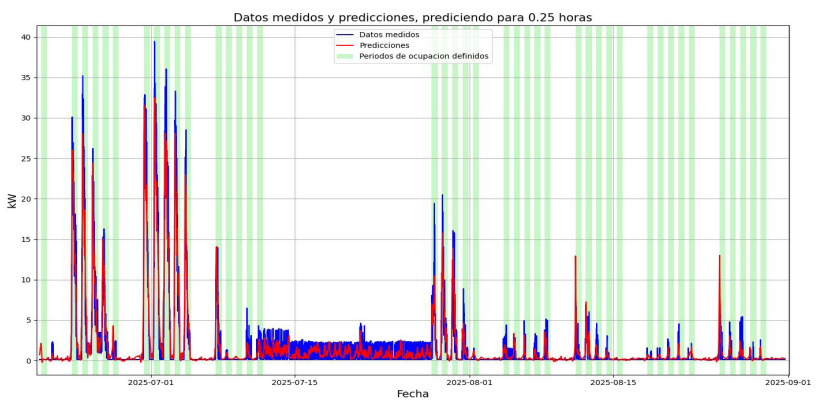 Figura 8: Datos medidos y predicciones para 15 minutos del modelo lb:48, h:24. junto con los periodos de ocupación del edificio, conjunto de datos de testeo.
Figura 8: Datos medidos y predicciones para 15 minutos del modelo lb:48, h:24. junto con los periodos de ocupación del edificio, conjunto de datos de testeo.
En la Figura 9, se observan recortes aleatorios de porciones del conjunto de datos, junto con las predicciones del modelo para las 6 horas posteriores, comparadas con los datos medidos para esas 6 horas. El modelo respeta las tendencias de los datos medidos sin capturar variaciones pequeñas de los mismos, como si se tratase de una versión "suavizada" del comportamiento del consumo.
En la Figura 10, se observan gráficos de dispersión para diferentes horizontes de predicción del modelo. Las métricas empeoran a medida que crece el horizonte de predicción (futuro más lejano), como se observa de la evolución del nRMSE de Figura 11.
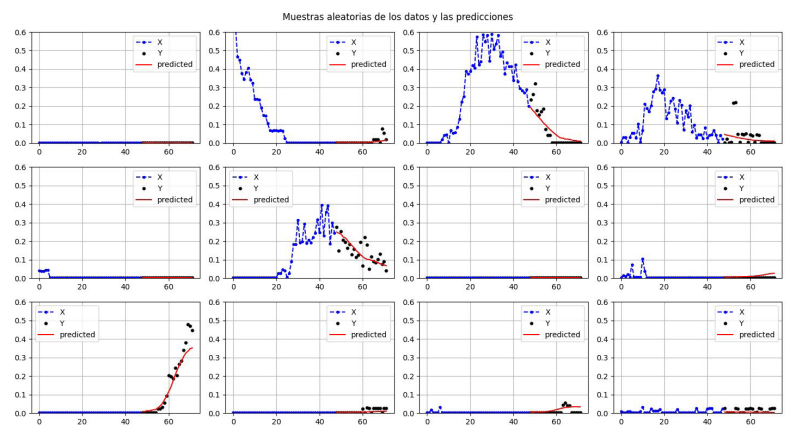 Figura 9: Muestras aleatorias de datos medidos y predicciones para 6 h por el modelo lb:48, h:24.
Figura 9: Muestras aleatorias de datos medidos y predicciones para 6 h por el modelo lb:48, h:24.
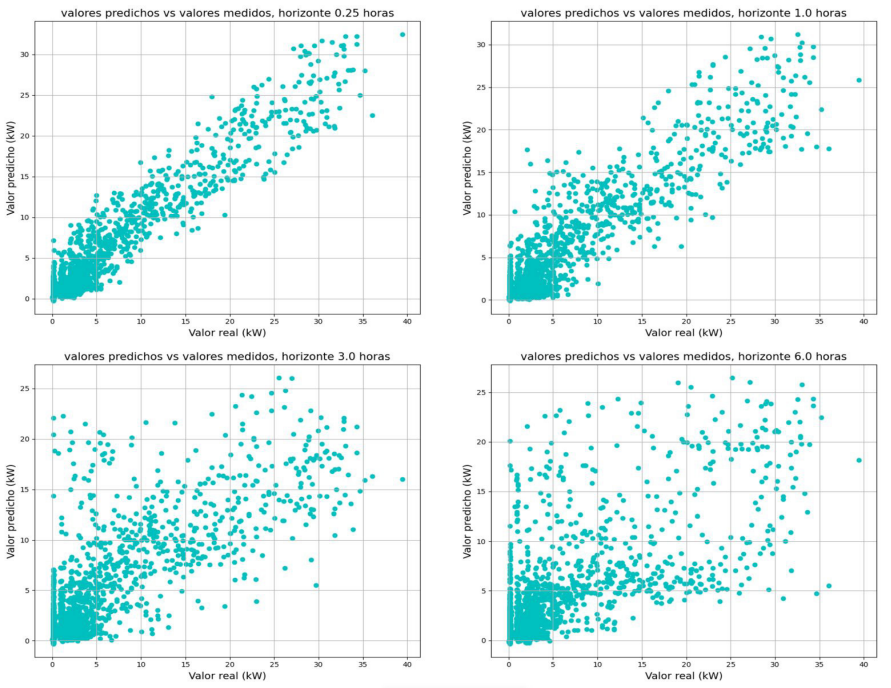 Figura 10: Dispersión de valores medidos vs predichos, para predicciones a 15 min, 1 h, 3h y 6h.
Figura 10: Dispersión de valores medidos vs predichos, para predicciones a 15 min, 1 h, 3h y 6h.
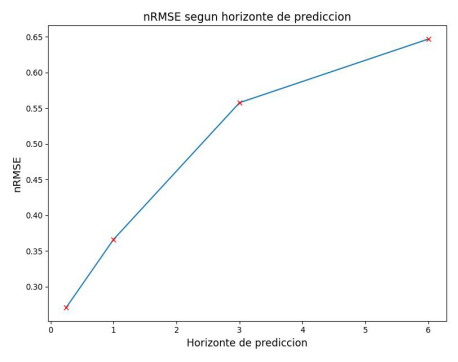 Figura 11: Cambio en el valor de nRMSE en función de diferentes horizontes de predicción.
Figura 11: Cambio en el valor de nRMSE en función de diferentes horizontes de predicción.
Discusión
Tratamiento de datos faltantes
Las gráficas de evolución de la función de pérdida durante el entrenamiento, tanto de temperatura como de radiación solar, observados en la Figura 5, muestran una convergencia adecuada del modelo y una diferencia leve entre los conjuntos de entrenamiento y validación, lo que podría señalar que el modelo no sobreajusta a los datos de entrenamiento (overfitting). Además, en el proceso de adaptación al sitio, existe una correspondencia cercana a la lineal entre variables del mismo tipo.
En particular, para la irradiancia solar, existen diversos filtros y controles de calidad, los cuales no han sido utilizados en este trabajo. En función de mejorar la calidad de las predicciones, se plantea a futuro la implementación de estas metodologías de control en los datos de irradiancia solar.
Predicción de datos de consumo eléctrico
En cuanto a las predicciones realizadas para el consumo eléctrico en el edificio, todos los modelos, incluido el seleccionado para reentrenamiento, presentan una desviación estándar σr < 1, lo que explica la subestimación de la mayoría de los picos de consumo de potencia eléctrica en las predicciones. En línea con este análisis, el diagrama de Taylor surge como una herramienta intuitiva y de fácil visualización para la evaluación del rendimiento y la selección de modelos.
Para trabajos futuros, sería de utilidad evaluar modelos con otras estructuras para hacer predicciones de consumo, considerando que los lookbacks y horizons más extensos, podrían requerir modelos de estructura mayor (mayor cantidad de datos de entrada y salida) para realizar predicciones de consumo a horizontes mayores sin perder precisión. Esto con la desventaja de un mayor costo computacional asociado al entrenamiento. Además, los modelos con mayores lookbacks (cantidad de datos pasados) podrían necesitar mayor cantidad de épocas de entrenamiento para un rendimiento óptimo, o bien, la estructura del modelo habría alcanzado su rendimiento máximo para ese número de datos de entrada, viéndose obligada a aprender patrones más generales de estos conjuntos de datos de entrada más grandes.
Se observó que el error de predicción aumenta junto con el horizonte, esto es algo esperable debido al funcionamiento del modelo, el cual utiliza el primer dato predicho para realizar la predicción del segundo, y así sucesivamente para todas las predicciones en el horizonte definido. Por lo tanto, el error cometido en cada una de las predicciones influye en las siguientes, creciendo con cada nueva predicción, esto se observa de manera clara en los gráficos de dispersión. Este funcionamiento también explica la mayor subestimación de los picos a medida que se aumenta el horizonte de predicción, debido a que, incluso en los primeros horizontes de predicción, el modelo tiende a subestimar.
Conclusiones
El uso de herramientas de machine learning surge como una alternativa de alto rendimiento para la correlación, adaptación al sitio e imputación de series de datos climáticos medidos en un sitio determinado.
En este trabajo se realizó la imputación de un faltante en las series de temperatura ambiente, mediante datos de la estación meteorológica del SMN, y de radiación solar, mediante datos satelitales.
Se obtuvieron medidas de errores satisfactorias para el desarrollo de este trabajo.
Mediante la generación de modelos basados en redes neuronales recurrentes del tipo LSTM, se realizaron estimaciones a horizontes futuros (forecasting) de potencia eléctrica consumida en el edificio de Rectorado de la UNSa.
Para ello, se evaluaron 16 modelos, para cuatro diferentes lookbacks y cuatro horizontes de predicción.
Se mantuvo fija la arquitectura del modelo en cuanto a las variables de entrada, capas ocultas y neuronas.
Se ha incluido, en el conjunto de variables utilizadas para entrenar el modelo, una variable codificada para identificar días de la semana, recesos académicos y administrativos, y otra variable codificada para identificar horarios de ocupación de las oficinas.
Entre los modelos entrenados, el óptimo considerando un compromiso entre costo computacional y alcance del horizonte de predicción, fue el que utilizó un lookback de 12 horas y un horizonte máximo de 6 horas.
El modelo entrenado fue capaz de identificar los periodos de utilización del edificio, realizando predicciones de consumo acordes al nivel correspondiente de utilización.
Por esto, se concluye que es aconsejable utilizar una variable temporal que permita considerar el día de la semana y la hora del día para mejores estimaciones, sobre todo a horizontes de mayor extensión.
Como era de esperarse, los modelos en su conjunto presentaron un mejor desempeño al predecir horizontes de corto plazo.
Esto se debe a que toda su estructura se utiliza para una predicción de menor extensión en cantidad de pasos temporales.
Como una propuesta a futuro, surge el análisis de desempeño del modelo teniendo en cuenta variables adicionales como humedad relativa o velocidad de viento.
También podrían utilizarse variables internas, por ejemplo, datos de temperatura o humedad internas del edificio, las cuales pueden suponer un aumento del rendimiento y robustez del modelo.
Posteriormente se podrían implementar estrategias de control predictivo para sistemas HVAC, evaluando su nivel de impacto.
Notas
Referencias
- Abu-Mostafa, Y. S., Magdon-Ismail, M., & Lin, H. 2012. Learning from Data. https://dl.acm.org/citation.cfm?id=2207825
- Bourdeau, Mathieu, Xiao Qiang Zhai, Elyes Nefzaoui, Xiaofeng Guo, y Patrice Chatellier. 2019. «Modeling and Forecasting Building Energy Consumption: A Review of Data-Driven Techniques». Sustainable Cities and Society 48:101533. doi:10.1016/j.scs.2019.101533.
- International Energy Agency. 2025. Global Energy Review 2025, IEA, Paris https://www.iea.org/reports/global-energy-review-2025, Licence: CC BY 4.0.
- Joseph, M. (2022). Modern Time Series Forecasting with Python: Explore Industry-Ready Time Series Forecasting Using Modern Machine Learning and Deep Learning. Packt Publishing.
- Kim J. Moon J. Hwang E, Kang P. 2019. Recurrent inception convolution neural network for multi short-term load forecasting. Energy and Buildings; 194: 328-41.
- Kingma, Diederik & Ba, Jimmy. (2014). Adam: A Method for Stochastic Optimization. International Conference on Learning Representations.
- Rumelhart, David E., Geoffrey E. Hinton, y Ronald J. Williams. 1986. «Learning Representations by Back-Propagating Errors». Nature 323(6088):533-36. doi:10.1038/32353330.
- Salazar, Germán Ariel, Rubén Darío Ledesma, Constanza López Ruiz, y Olga De Castro Vilela. 2025. «Análisis de desempeño de diferentes técnicas de aprendizaje automático en una adaptación al sitio de irradiancia solar global para Salta (Argentina)», en Avances en Energías Renovables y Medio Ambiente. Vol. 28.
- Servicio Meteorológico Nacional | Argentina.gob.ar. s. f. Recuperado 11 de septiembre de 2025. https://www.argentina.gob.ar/smn.
- SODA PRODUCTS. s. f. Recuperado 11 de septiembre de 2025. https://www.soda-pro.com.
- Uhrig, M., Vignolo, L., & Müller, O. (2025). Modelado y predicción de la demanda eléctrica: comparación de enfoques estadísticos y de aprendizaje automático. SADIO Electronic Journal of Informatics and Operations Research, 24(I), eo67. https://doi.org/10.24215/151467742067
- Zainali, S., Yang, D., Landelius, T., & Campana, P. E. 2023. Site adaptation with machine learning for a Northern Europe gridded global solar irradiance product. Energy And Al, 15, 100331. https://doi.org/10.1016/j.egyai.2023.100331